#install.packages("rvest")
#install.packages("dplyr")
#install.packages("sf")
#install.packages("ggplot2")
#install.packages("gt")
#install.packages("stringr")
library(rvest)
library(dplyr)
library(sf)
library(ggplot2)
library(stringr)
library(gt)1 objetivos
neste tutorial, você aprenderá a criar um mapa da cidade de uberlândia utilizando a linguagem de programação R. nosso objetivo é demonstrar como visualizar a distribuição da população de uberlândia por bairro com base nos dados do censo demográfico do brasil de 2022.
ao final deste tutorial, você será capaz de:
- importar e preparar dados geográficos para análises no R;
- unir dados geográficos com dados demográficos para criar mapas;
- criar mapas utilizando a biblioteca
ggplot2; - representar a população de cada bairro de uberlândia por meio de uma escala de cores.
2 introdução
a representação de dados demográficos em mapas pode ser uma boa ferramenta para visualizar a distribuição espacial da população e identificar padrões de ocupação do território. ao combinar dados do censo com mapas, podemos analisar como a população se distribui nos diferentes bairros de uma cidade, identificando áreas de maior e menor densidade populacional, e relacionando esses padrões com outros fatores. neste tutorial, nosso foco será a cidade de uberlândia, localizada no estado de minas gerais. analisaremos como a população de uberlândia está distribuída espacialmente e identificaremos os bairros mais populosos da cidade.
3 preparação do ambiente
para seguir este tutorial, você precisará ter o R e o RStudio instalados em seu computador. para este projeto, eu usei a versão 4.1.1 do R e a versão 2024.09.0+375 do RStudio. você pode baixar o R aqui e o RStudio aqui.
além disso, utilizaremos os seguintes pacotes:
rvest: para web scraping;dplyr: para manipulação de dados;sf: para manipulação de dados espaciais;ggplot2: para visualização de dados;gt: para criação de tabelas;stringr: para manipulação de texto.
caso você não tenha algum desses pacotes instalados, você pode instalá-los utilizando o comando install.packages("nome_do_pacote"). no código abaixo, os comandos de instalação estão como comentário. para instalar qualquer pacote, basta remover o caractere # da linha correspondente e executar o código.
4 obtenção dos dados
para criar um mapa da população de cada bairro de uberlândia, precisamos de dois conjuntos de dados:
um arquivo shapefile com as informações geográficas dos bairros da cidade (um arquivo shapefile é um formato padrão para representar dados geográficos vetoriais);
um arquivo com os dados da população total de cada bairro;
após a obtenção desses dados, vamos combinar as informações geográficas com os dados da população para criar o mapa; para unirmos os dados, é necessário que ambos os conjuntos de dados tenham uma variável em comum, que será utilizada como chave de ligação; em nosso caso, a variável em comum será o nome do bairro e, por isso, precisamos garantir que os nomes dos bairros estejam iguais em ambos os conjuntos de dados.
4.1 obtenção do shapefile dos bairros de uberlândia
o site da prefeitura de uberlândia disponibiliza um arquivo dwg com as divisões dos bairros da cidade; o R não consegue ler diretamente arquivos dwg que são específicos para softwares de desenho técnico como o autocad. por isso, é necessário converter o arquivo para o formato shapefile (.shp), que é amplamente utilizado em sistemas de informação geográfica e pode ser facilmente lido no R utilizando o pacote sf. existem algumas ferramentas na web que convertem gratuitamente um arquivo dwg para shapefile. mas não seguiremos por este caminho. o ibge divulgou recentemente arquivos shapefile com as divisões dos bairros de algumas cidades brasileiras, incluindo uberlândia. estes arquivos estão disponíveis no site do ibge no item Arquivo geoespacial de Bairros – Brasil. após baixar o arquivo da página do ibge, vamos descompactá-lo e importar o arquivo shapefile para o R.
bairrosBR <- st_read("BR_bairros_CD2022/BR_bairros_CD2022.shp")ao investigar a estrutura do objeto bairrosBR a partir da função str(bairrosBR), podemos ver que os nomes dos municípios estão na coluna NM_MUN e que os nomes dos bairros estão na coluna NM_BAIRRO. vamos filtrar apenas as observações que correspondam à cidade de uberlândia:
udiaIBGE <- bairrosBR[bairrosBR$NM_MUN == "Uberlândia",]o conjunto de dados udiaIBGE contém apenas informações de uberlândia. novamente, a partir da estrutura do conjunto, podemos ver que as coordenadas geográficas dos bairros da cidade estão na coluna geometry. esta variável é do tipo sfc_MULTIPOLYGON, que é um tipo de objeto espacial que apresenta as coordenadas dos polígonos que representam os bairros. o ggplot2 consegue reunir todos estes polígonos de forma simples. vejamos:
ggplot(udiaIBGE) +
geom_sf()
podemos aprimorar a visualização do mapa removendo elementos desnecessários e ajustando as cores dos polígonos e das linhas que representam as fronteiras dos bairros. para isso, utilizaremos a função theme_void() para remover as coordenadas dos eixos x e y e o fundo cinza padrão. além disso, preencheremos os polígonos (bairros) com a cor branca e destacaremos as fronteiras entre os bairros com linhas pretas.
ggplot(udiaIBGE) +
geom_sf(fill = "white", color = "black") +
theme_void()
a partir do mapa acima, podemos adicionar uma nova camada para localizar um bairro específico. a seguir, localizaremos o bairro santa mônica.
ggplot(udiaIBGE) +
geom_sf(fill = "white", color = "black") +
theme_void() +
geom_sf(data = udiaIBGE[udiaIBGE$NM_BAIRRO == "Santa Mônica",], fill = "#BE5103", color = "black")
4.2 obtenção dos dados da população por bairro
uma matéria publicada no dia 15 de novembro de 2024 no portal g1 apresenta uma tabela com a população de 75 bairros de uberlândia. esses dados foram obtidos a partir do censo demográfico 2022. vamos raspar essa tabela e utilizá-la para criar o mapa da população de uberlândia. para a raspagem, utilizaremos o pacote rvest.
analisando a matéria do g1, podemos identificar duas tabelas no texto. a segunda tabela contém os dados da população de todos os bairros. para raspar essa tabela e armazenar os dados em um data frame, precisamos primeiro identificar sua localização no código html da página. ao inspecionar o elemento (clique com botão direito sobre a tabela e selecione “inspecionar” ou “inspecionar elemento”), observamos que a segunda tabela está contida em uma tag <table> que, por sua vez, está dentro de uma tag <div> com id igual a chunk-cmqe5. usaremos esses seletores css para extrair precisamente os dados desejados.
url <- "https://g1.globo.com/mg/triangulo-mineiro/noticia/2024/11/15/cinco-bairros-mais-populosos-de-uberlandia-concentram-20percent-da-populacao-da-cidade-veja-lista.ghtml"
html <- read_html(url)
tabela <- html |>
html_elements("div#chunk-cmqe5") |>
html_elements("table") |>
html_table()o objeto tabela é uma lista de data frames, onde cada elemento da lista corresponde a uma tabela raspada da página. como utilizamos seletores css específicos (div#chunk-cmqe5 e table), apenas a tabela que nos interessa foi capturada. vamos verificar a estrutura do objeto tabela.
str(tabela)List of 1
$ : tibble [76 × 2] (S3: tbl_df/tbl/data.frame)
..$ X1: chr [1:76] "Bairro" "Santa Mônica" "Shopping Park" "São Jorge" ...
..$ X2: chr [1:76] "População" "37.665" "30.240" "29.578" ...a partir da estrutura de tabela, verificamos, de fato, que existe apenas um elemento na lista e, por isso, nosso conjunto de interesse pode ser acessado a partir de tabela[[1]]:
print(tabela[[1]], n = 5)# A tibble: 76 × 2
X1 X2
<chr> <chr>
1 Bairro População
2 Santa Mônica 37.665
3 Shopping Park 30.240
4 São Jorge 29.578
5 Morumbi 25.898
# ℹ 71 more rowsa impressão acima revela dois problemas na estrutura dos dados:
- os nomes das colunas (“Bairro” e “População”) foram interpretados incorretamente como dados na primeira linha;
- as colunas foram nomeadas automaticamente como
X1eX2.
para preparar os dados para a combinação com as informações geográficas, precisamos:
remover a primeira linha do data frame, que contém os nomes originais das colunas;
renomear as colunas para corresponderem às do arquivo geográfico:
renomear
X1para NM_BAIRRO (nome do bairro);renomear
X2para POP (população).
essa padronização dos nomes é essencial para a combinação dos conjuntos de dados, pois a coluna NM_BAIRRO servirá como chave de ligação entre os dados populacionais e o arquivo geográfico udiaIBGE.
pop_bairros <- tabela[[1]]
pop_bairros <- pop_bairros[-1,]
colnames(pop_bairros) <- c("NM_BAIRRO", "POP")nossa trabalho com os dados da população ainda não está finalizado. a coluna POP foi importada como uma string e contém pontos como separadores de milhar.
str(pop_bairros)tibble [75 × 2] (S3: tbl_df/tbl/data.frame)
$ NM_BAIRRO: chr [1:75] "Santa Mônica" "Shopping Park" "São Jorge" "Morumbi" ...
$ POP : chr [1:75] "37.665" "30.240" "29.578" "25.898" ...uma conversão direta dessa variável para a classe numérica usando as.numeric() resultaria em valores incorretos (por exemplo, o valor 37.665 seria interpretado como 37,665 ao invés do valor correto 37665). para corrigir esse problema, removeremos os pontos da coluna POP e, em seguida, converteremos a coluna para um objeto numérico. para a remoção dos pontos, utilizaremos uma expressão regular. em expressão regular (regex), o ponto . é um caractere especial que representa qualquer caractere único, exceto uma nova linha. para representar um ponto literal, precisamos escapá-lo com uma barra invertida \. dessa forma, a expressão regular em R "\\." representa um ponto literal. a função str_replace_all() do pacote stringr permite substituir todos os pontos por uma string vazia "". após a remoção dos pontos, utilizaremos a função as.numeric() para converter a coluna POP para um objeto numérico.
pop_bairros <- pop_bairros |>
mutate(POP = as.numeric(str_replace_all(POP, "\\.", ""))) # remove pontos e converte para numérico
str(pop_bairros)tibble [75 × 2] (S3: tbl_df/tbl/data.frame)
$ NM_BAIRRO: chr [1:75] "Santa Mônica" "Shopping Park" "São Jorge" "Morumbi" ...
$ POP : num [1:75] 37665 30240 29578 25898 23224 ...tudo certo! a função gt() nos permite exibir, em formato de tabela, os dez bairros mais populosos de uberlândia.
expandir código da tabela
pop_bairros |>
arrange(desc(POP)) |>
head(10) |>
gt() |>
cols_label(
NM_BAIRRO = "Bairro",
POP = "População"
) |>
cols_align(align = "center",
columns = POP)| Bairro | População |
|---|---|
| Santa Mônica | 37665 |
| Shopping Park | 30240 |
| São Jorge | 29578 |
| Morumbi | 25898 |
| Laranjeiras | 23224 |
| Presidente Roosevelt | 20198 |
| Jardim Canaã | 18073 |
| Segismundo Pereira | 17077 |
| Jardim Brasília | 16618 |
| Jardim Europa | 16212 |
4.3 unindo os dados
já obtemos os dados geográficos e os dados da população de cada bairro de uberlândia. agora, vamos combinar esses dois conjuntos de dados para criar o mapa da população de uberlândia. para isso, utilizaremos a função left_join() do pacote dplyr para unir os data frames, usando a coluna NM_BAIRRO como chave de ligação. entretanto, antes de realizar a junção, é importante verificar se os nomes dos bairros estão padronizados em ambos os conjuntos. essa verificação é crucial pois qualquer diferença na grafia (incluindo acentos ou maiúsculas/minúsculas) pode impedir a correta combinação dos dados.
sum(!(udiaIBGE$NM_BAIRRO %in% pop_bairros$NM_BAIRRO))[1] 1o resultado acima indica que existe um bairro em udiaIBGE que não está presente em pop_bairros. vamos identificar esse bairro:
udiaIBGE$NM_BAIRRO[!(udiaIBGE$NM_BAIRRO %in% pop_bairros$NM_BAIRRO)][1] "Pacaembú"pop_bairros$NM_BAIRRO[!(pop_bairros$NM_BAIRRO %in% udiaIBGE$NM_BAIRRO)][1] "Pacaembu"a comparação revela que o problema está na grafia do bairro ‘Pacaembú’. este bairro aparece:
- em
udiaIBGEcomo ‘Pacaembú’ (com acento); - em
pop_bairroscomo ‘Pacaembu’ (sem acento).
precisamos padronizar essa grafia antes de realizar a junção dos conjuntos de dados para garantir que as informações desse bairro sejam corretamente combinadas.
pop_bairros$NM_BAIRRO <- pop_bairros$NM_BAIRRO |>
str_replace("Pacaembu", "Pacaembú") # corrige grafia do bairro Pacaembú
dados_completos <- udiaIBGE |>
left_join(pop_bairros, by = "NM_BAIRRO") # combina os dados5 criando o mapa
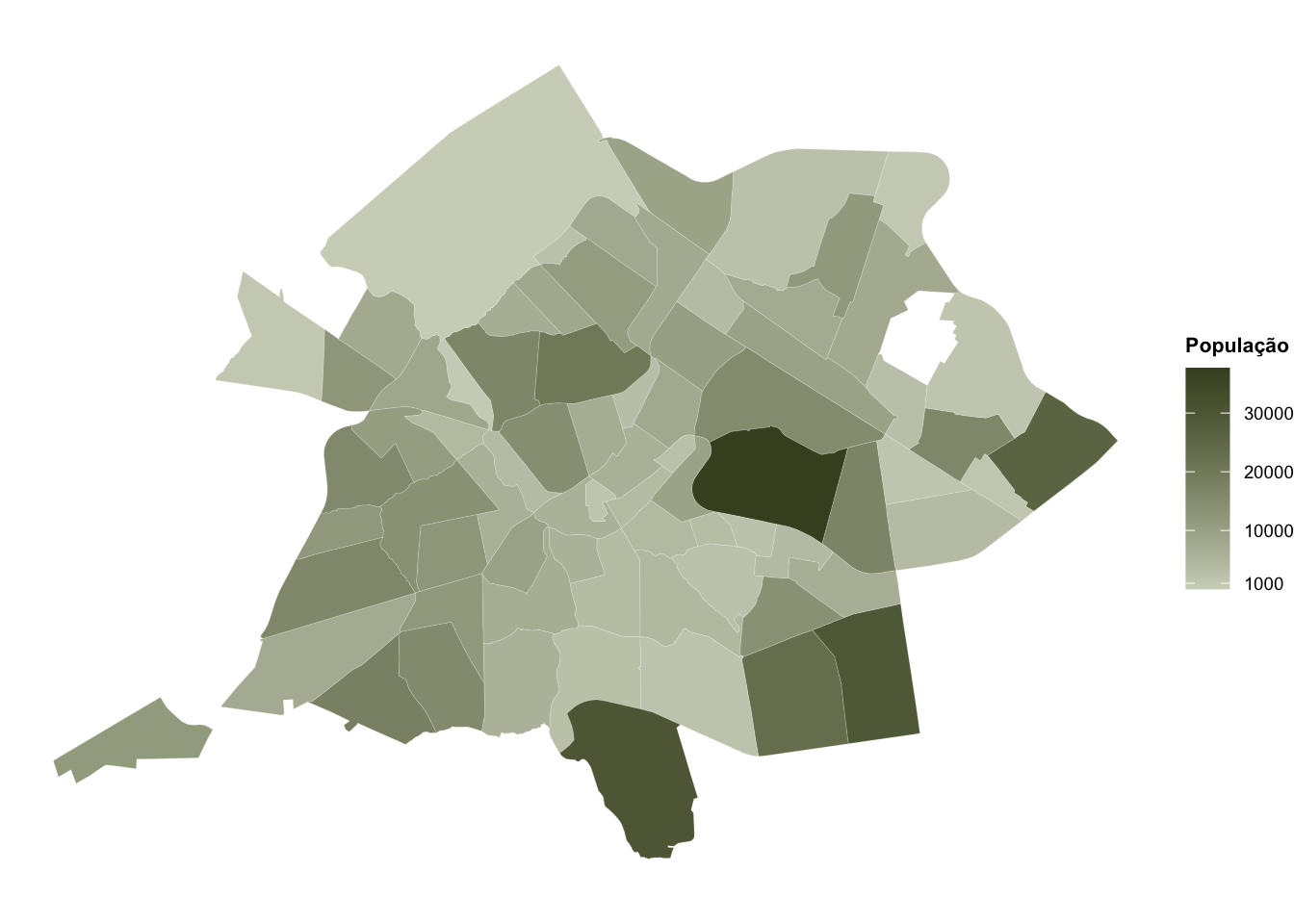
agora que temos os dados completos, podemos criar o mapa da população de uberlândia. para representar a população de cada bairro, utilizaremos uma escala de cores, onde os bairros com maior população serão representados por cores mais escuras. para isso, utilizaremos a função scale_fill_gradient() para definir a escala de cores.
dados_completos |>
ggplot()+
geom_sf(aes(fill = POP), color = "white", linewidth = 0.03)+ # Adiciona contorno branco fino
scale_fill_gradient(
high = "#454f27", # Verde escuro para alta população
low = "#d0d4c3", # Verde claro para baixa população
name = "População", # Título da legenda
breaks = c(1000, 10000, 20000, 30000) # níveis da escala
)+
theme_void()+ # tema mais limpo
theme(
legend.title = element_text(size = 8, face = "bold"), # tamanho e estilo do título da legenda
legend.text = element_text(size = 7) # tamanho do texto da legenda
)
para facilitar nossa análise, poderíamos, por exemplo, adicionar ao mapa o nome dos bairros mais populosos. para isso, acrescentaríamos ao mapa anterior a camada de labels a partir da função geom_sf_label().
mais_populosos <- dados_completos |>
arrange(desc(POP)) |>
head(10) # conjunto com os 10 bairros mais populosos
mais_populosos$NM_BAIRRO <- mais_populosos$NM_BAIRRO |>
str_replace("Presidente Roosevelt", "Roosevelt") # troca nome do bairro Presidente Roosevelt por Roosevelt para melhor visualização
dados_completos |>
ggplot()+
geom_sf(aes(fill = POP), color = "white", linewidth = 0.03)+ # adiciona contorno branco fino
scale_fill_gradient(
high = "#454f27", # cor para alta população
low = "#d0d4c3", # cor para baixa população
name = "População", # título da legenda
breaks = c(1000, 10000, 20000, 30000) # formata números com vírgula
)+
theme_void()+ # tema mais limpo para mapas
theme(
legend.position = "right",
legend.title = element_text(size = 8, face = "bold"),
legend.text = element_text(size = 7)
)+
geom_sf_label(data = mais_populosos, aes(label = NM_BAIRRO), size = 2)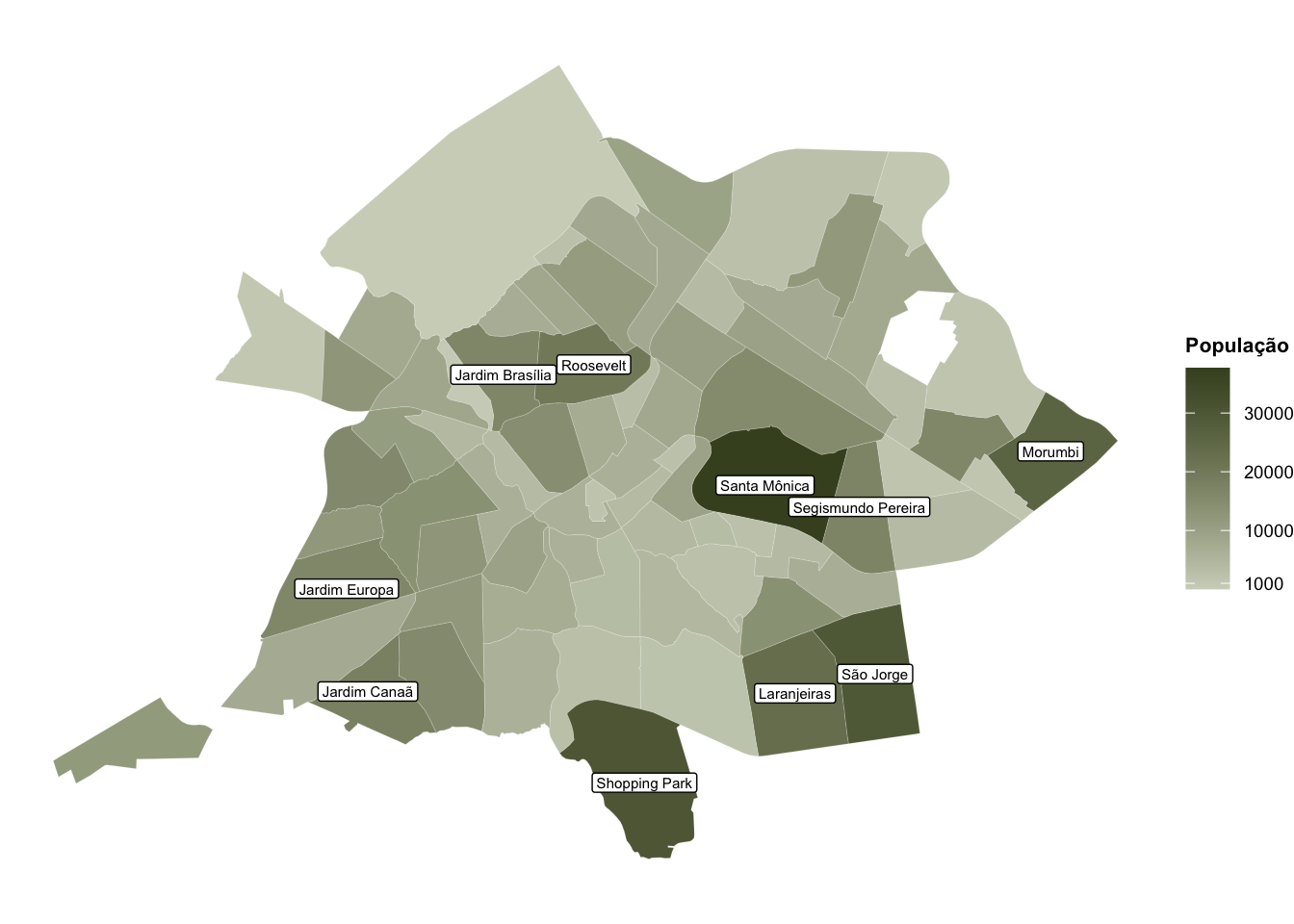
6 conclusão
neste tutorial, aprendemos a criar um mapa da cidade de uberlândia utilizando a linguagem de programação R. por meio dos dados do censo demográfico 2022, representamos visualmente a distribuição populacional por bairro da cidade. a combinação de informações geográficas com dados demográficos nos permitiu não apenas visualizar a distribuição espacial da população, mas também identificar padrões de ocupação do território urbano.
na análise dos dez bairros mais populosos, constatamos uma característica interessante: seis deles estão localizados nos limites da cidade, sugerindo um processo de expansão urbana nas áreas periféricas. Dos quatro bairros restantes, dois concentram-se na região do campus santa mônica da universidade federal de uberlândia, evidenciando o impacto da presença universitária na densidade populacional dessa área.